2. MDP
Really useful link for learning RL and Game theory
Markov Decision Process
The Bellman Equation
- : discount factor
- : transition probability
- : reward
Policy Extraction : DECIDING HOW TO ACT
(提取最优action)
The multi-armed bandit problem
A mukti-armed bandit (also known as an N-armded bandit) is defined by a set of random variables where:
- such that is the arm of the bandit; and
- k the index of the play of arm
The idea is that a gambler iteratively plays rounds, obervaing the reward from the arm after each round, and can adjust their strategy each time. The aim is to maximize the sum of the rewards collected over all rounds.
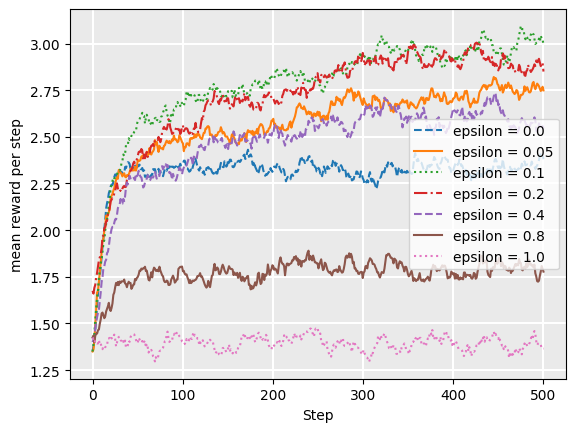
-greedy stragegy
- With probability wo choose the arm with maximum Q value (exploit).
- With brobability we choose a random arm with uniform probability (explore)
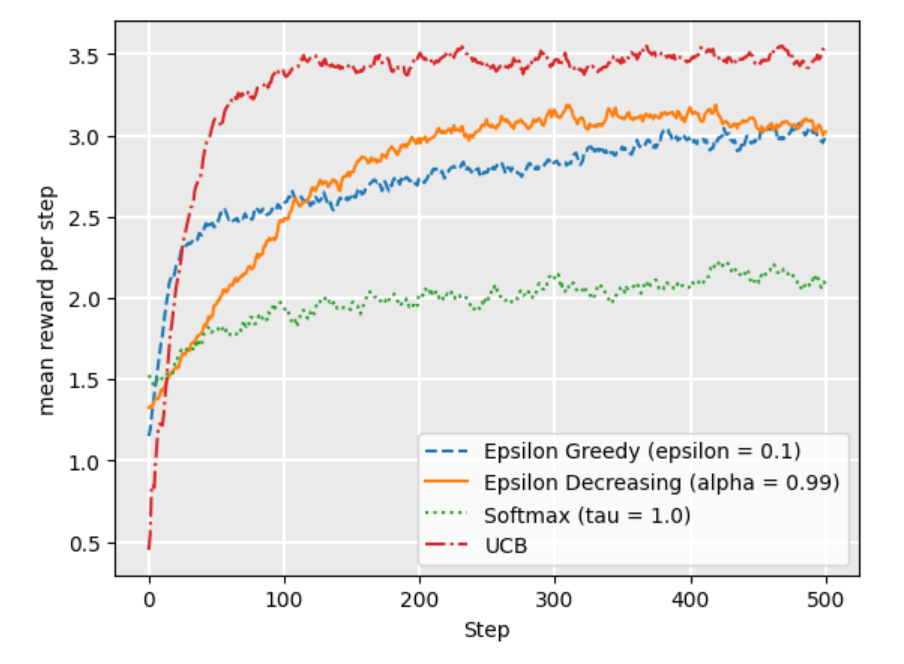
Softmax strategy
Softmax is a probability matching strategy, which means that the probability of each action being chosen is dependent on its Q-value so far.
UCB1 (upper condifence bounds) Using the UCB1 strategy, we select the next action using the following:
where is the number of rounds so far, and is the number of times has been chosen in all previous arounds.
- The left term encoueages exploitation: the Q-value is high for actions that have had a high reward
- The right term encourages exploration: it is high for actions that have been explored less, that is, when relative to other actions. As increases, if some actions have low , then the expression is large compared to actions with higher
Model-based vs model-free
Value iteration is part of a class of solutions known as model-based techniques. This means that we need to know the model, in particular, we have access to and .
How can we calculate a policy if we don't know the transitions and rewards? we learn through experience by trying actions and seeing what the result is, making this machine learning problem. We learn a value function or a policy directly.
Temporal-difference learning
Model-free reinforcement learning is learning a policy directly from experience and rewards. Q-learning and SARSA are two model-free approaches.
- : Learning rate
- : Reward
- : discount factor
Q-learning: Off-policy temporal difference learning
SARSA: On-policy temporal difference learning
Q-learning vs SARSA
- Q-Learning
- Q-learning will converge to the optimal policy
- But it can be 'unsafe' or risky during training.
- SARSA
- SARSA learns the safe policy, mayve not that optimal.
- SARSA receibes a higher average reward via training.
The difference between SARSA and Q-learning is that Q-learning is off-policy learning, while Sarsa is on-policy learning. Essentially, this means that SARSA chooses its action using the same policy used to choose the previous action, and then uses this difference to update its Q-function; while Q-learning updated assuming that the next action would be the action with the maximum Q-value.
Q-learning is therefore "optimistic", in that when it updates, it assumes that in the next state, the greedy action will be chosen, even it may be that in the next step, the policy, such as -greedy, will choose to explore an action other than the best.
SARSA instead knows the action that it will execute next when it performs the update, so will learn on the action whether it is best or not.
On-policy vs. off-policy: Why do we have both?
The main advantage of off-policy approaches is that they can use samples from sources other than their own policy. For example, off-policy agents can be given a set of episodes of behaviour from another agent, such as a human expert, and can learn a policy by demonstration.
n-step SARSA
Shape reward
The purpose of the function is to given an additional reward when any action transitions from state to . The function: providees heuristic domain knowledge to the problem that is typically manually programmed.
Potential based Reward Shaping
is the potential of state .
Important : discount factor on
Linear Q-function Arroximation
The key idea is to approximate the Q-function using a linear combination of features and their weights. Instead of recording everything in detail.
The overall process:
- for the states, consider what are the features that dettermine its representation;
- during learning, perform updates based on the weights of features indtead of states; and
- estimate by summing the features and their weights.
Rrepresentation
- A feature vector, which is a vector of different features, where is the number of features and is the number of actions.
It is straightforward to construct state pair features from just state features.
This effectively results in different weight vectors:
- A weight vector of size : One weight for each feature-action pair. ia$.
Q-values from linear Q-function
Given a feature vector and a weight vector , the Q-value of a state is a linear combinations of features and weights.
Linear Q-function update
can be altered depand on the algorthm used.
- A action only updates the weights corresponded to the features of the action.
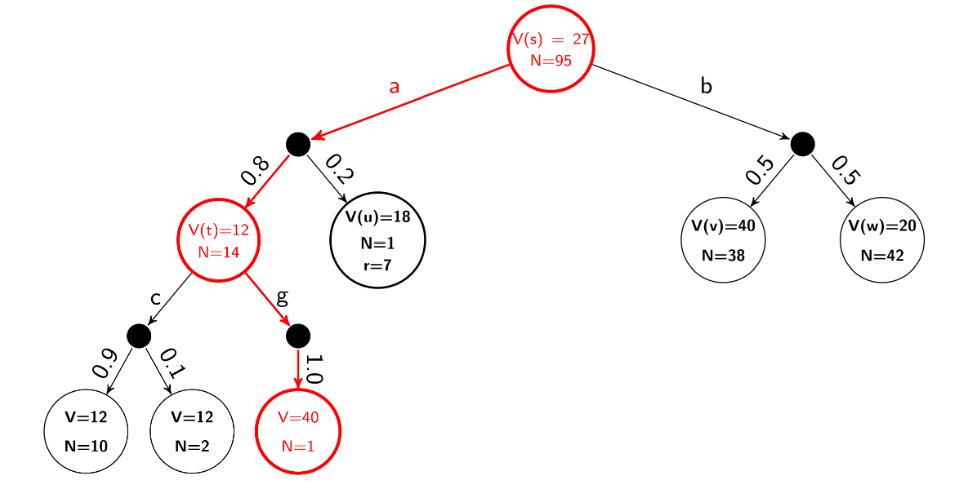
Monte Carlo Tree Search
Value updation for expectimax tree