5. Cross validation
Cross validation
Compare different algorithms in terms of performance from limited available data and help choose hyperparameters for an algorithm
Performance matrices
- Given a dataset of n samples.
- For a data point we predict
Matrices in regression
- Mean squared error:
- Root mean squared error:
- Mean absolute error:
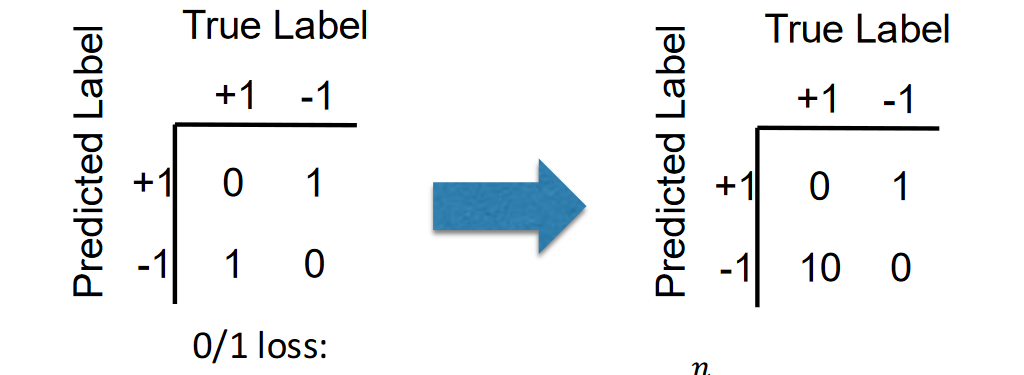
Performance metrics in classification
| True Label +1 | True Label -1 | |
|---|---|---|
| Predicted +1 | TP | FP |
| Predicted -1 | FN | TN |
- Accurcy: (𝑇𝑃 + 𝑇𝑁) / (𝑇𝑃 + 𝐹𝑃 + 𝐹𝑁 + 𝑇𝑁)
- Error: (𝐹𝑃 + 𝐹𝑁)/(𝑇𝑃 + 𝐹𝑃 + 𝐹𝑁 + 𝑇𝑁)
- Recall/Sensitivity: 𝑇𝑃/(𝑇𝑃 + 𝐹𝑁)
- Precision 𝑇𝑃/(𝑇𝑃 + 𝐹𝑃)
- Specificity 𝑇𝑁/(𝑇𝑁 + 𝐹𝑃)
- F1-score: 2 𝑃𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 × 𝑅𝑒𝑐𝑎𝑙𝑙/(𝑃𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 + 𝑅𝑒𝑐𝑎𝑙𝑙)
Receiver Operating Characteristic (ROC)
Summarized with an Area Under the Curve (AUC):
- Random: 0.5
- Perfect Classifier: 1
Modified loss function
Different misclassification have difference influence
Predicting a diseased patient as healthy has much worse serious consequences than predicting a diseased patient as healthy!!!
Cross-validation: using “unseen” data
Split datasets in three parts
| Training Set | Validation Set | Test Set |
|---|
K-Fold Cross Validation
- Split training data into disjoint sets
- Either randomly, or in a fixed fashion
- If has samples, then each fold has approximately samples
- Popular choices: (leave one out)
- For
- train with sets
- test on set
- let be the test metric (e.g., accuracy, MSE)
Mean variance
0.632 Bootstrapping
Let , and be the number of training samples in
- For :
- Pick n samples from with replacment, call it ( might contain the same sample more than once)
- train with set
- test on the remaining samples
- let be the test metric (e.g., accuracy, MSE)
Mean variance
- not picking one particular item in 1 draw is 1 − 1/𝑛
- not picking one particular item in 𝑛 draws is
- picking one particular item in 𝑛 draws is
Finally:
Nested Cross-valdation
- Useful for hyperparameter tuning
- Inner cross-vaildation (e.g., 0.632 bootstapping) to try different hypermarameters
- Outer cross-validation (e.g., k-folds) to report metric using the best hyptermenter
Hypothesis testing
- Let be mean and variance of algorithms 1 and 2
v using upper bound, degrees of freedom of Student's t-distribution
Examples
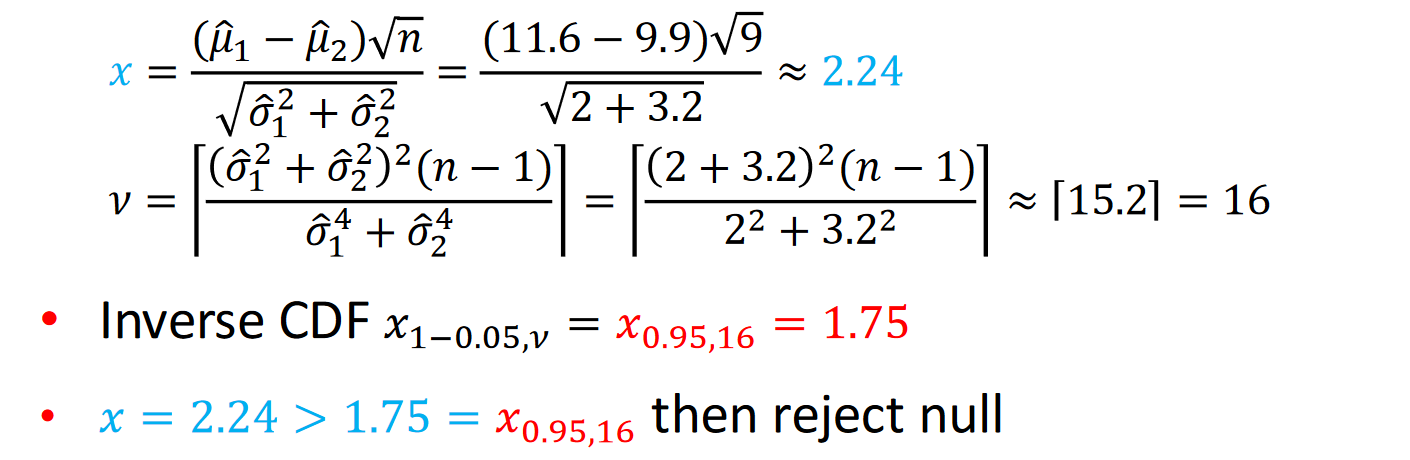
Learning with expert advice
In machine learning, the term "expert" typically refers to a model or algorithm with specialized knowledge or predictive ability for a specific task or domain.
Learning from expert advice
- Learner listens to some / all experts making decisions
- True outcomes are ADVERSARIAL
- Learner updates weights over experts based on their loses
- Algorithm all forms of "multiplicative weights"
- Nice clean bounds on total mistakes/losses: by "potential function" technique
Adversarial
- The real outcomes do not come from a fixed probability distribution, but rather may be chosen by an adversary attempting to make the learner fail. This is a conservative assumption that ensures the algorithm performs well even in worst-case scenarios. Under this setting, algorithms need to be adversarial, capable of handling the most unfavorable situations. potential function and clean upper bound Using potential functions, we can derive explicit upper bounds on the algorithm's cumulative number of mistakes or total loss.
Infallible expert(one always perfect)
- Majority Vote Algorithm
Imperfect experts(none guaranteed perfect)-incresingly better
- Weighted Majority Vote Algorithm by Halving
- Weighted Majority Voting by General Multiplicative Weights
- Probabilistic Experts Algorithm
Infallible Expert Algorithm: Majority Vote
- Initialzie set of experts who haven't made any mistakes
- Repeat per round
- Observe perdictions E_i for all
- Make majority prediction
- Overve correct outcome
- Remove mistaken experts from E
Mistake bound for Majority Vote Under infallible expert assumption, majiroty vote makes total misktakes
Imperfect experts and the Halving Algorithm
No more guarantee of an infallible expert
“Zero tolerance” dropping experts on a mistake is No sense
Imperfect experts: Halving Algorithm
- Initialize weight of expert
- Repeat per round
- Observe predicitions for all
- Make weighted majority prediction
- Oberve correct outcome
- Downweigh each mistaken expert
Mistake bound for Halving
If the best expert makes m mistakes, then weighted majority vote makes mistakes
From Halving to Multiply weights by
- Initialize weight of expert
- Repeat per round
- Observe predicitions for all
- Make weighted majority prediction
- Oberve correct outcome
- Downweigh each mistaken expert
Mistaken bound for
If the best expert makes mistakes, then weighted majority vote makes mistakes
Mini Conclusion
In the case of imperfect experts, the number of mistakes made by the weighted majority algorithm depends on the number of mistakes made by the best expert 𝑚, and the coefficient 2 in this dependency relationship is unavoidable.
The probabilistic experts algorithm
- Change 1: change from mistakes to loss: of
- Change 2: Randomised algorithm means, bounding expected losses (It is a risk!)
- Initialize weight of expert
- Repeat per round
- Oberve predicitons for all
- Predict of expert i with probability where
- Observe losses
- Update each weight
Expected loss bound
Expected loss of probalistic expert alghorithm is where is the minimum loss over experts
MAB
Where we learn to take actions; we receive only indirect supervision in the form of rewards
Multi-Armed Bandit
- Simplest setting for balancing exploration, exploitation
- Same familiy of ML tasks as reinforcement learning
Stochastic MAB setting
Possible actions called "arms"
- Arm i has distributon on bounded rewards with mean
In round :
- Play action
- Receive reward
Goal: minimize cumlative regret
- where
Greedy
At round t,
- Estimate value of each arm i as average reward observed
Some init constant used until arm i has been puolled
Eploit!
- Greedy
At round t
- Estimate value of each arm as average reward observed (Q- value function is same as greedy)
Exloit:
controls exploration vs. exploitation
- Larger will increase the change to exploration
- Smaller will tend to choose exploitation
Upper-Confidence Bound (UCB)
Some init constant used until arm i has been puolled