1. Linear regression, Logistic regression, MLE
Linear Regression
Model:
- Criterion: minimise the sum of squared errors
Expressed as matrix form:
where
thus
Maximum-likelihood estimation: Choose parameter values that maximise the probability of observed data
Maximising log-likelihood as a function of 𝒘 is equivalent to minimising the sum of squared errors
Solving for 𝒘 yields:
denotes transpose
should be an invertible matrix, that is: a full rank matrix, column vectorsw linear independence
Basis expansion for linear regression: Turn linear regression to polynomial regression for better fit the data
Logistic regression
Logistic regression assumes a Bernoulli distribution with parameter
and is a model for solving binary classification problems
MLE for Logistic regression cannot get an analytical solution.
We introduce: Approximate iterative solution
- Stochastic Gradient Descent (SGD)
- Newton-Raphson Method
Stochastic Gradient Descent (SGD)
Newton-Raphson Method
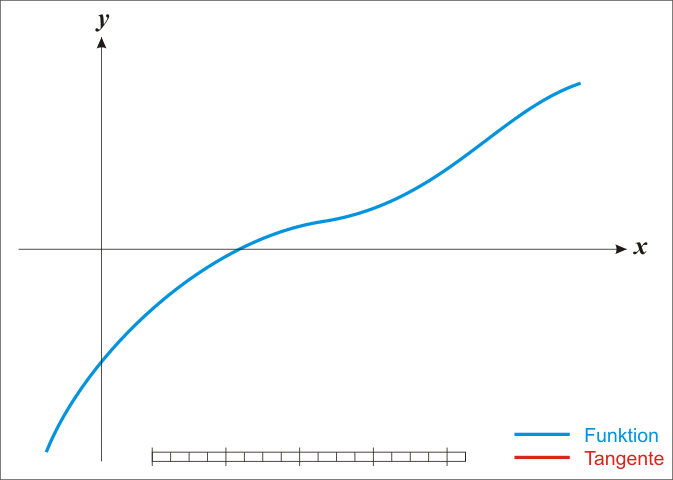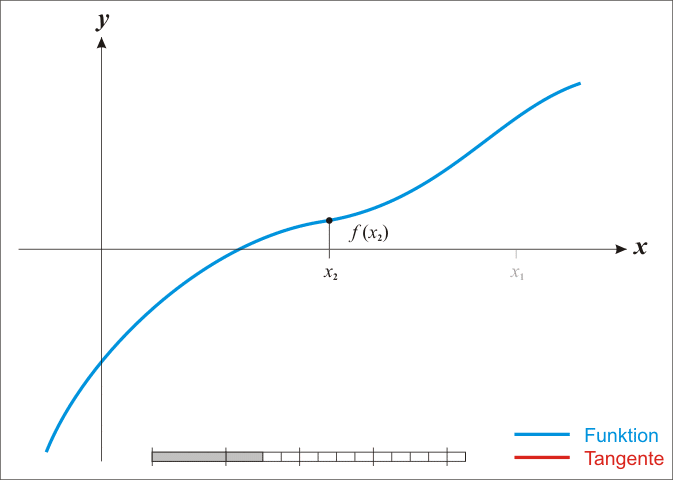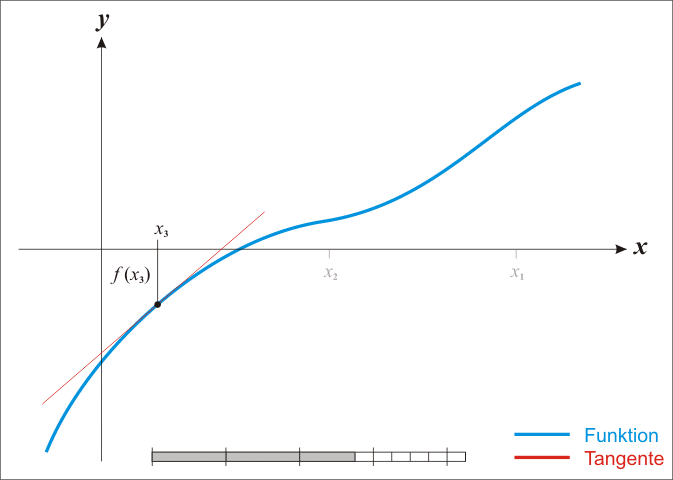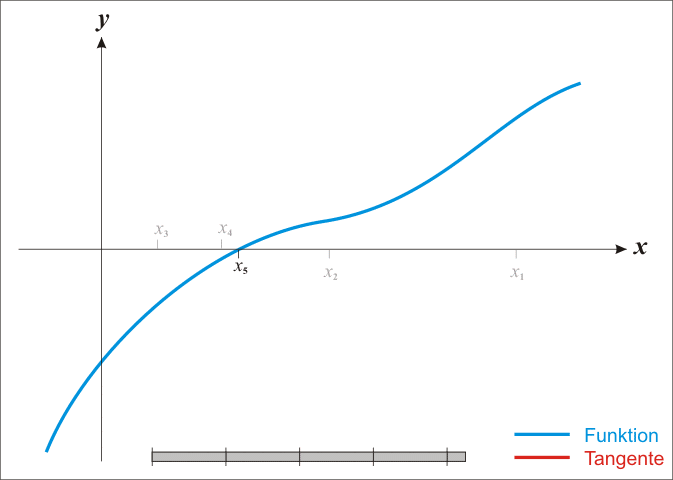
Regularization
Normal equations solution of linear regression:
With irrelevant/multicolinear features, matrix 𝐗!𝐗 has no inverse Regularisation: introduce an additional condition into the system
Adds λ to eigenvalues of 𝐗'𝐗: makes invertible : ridge regression
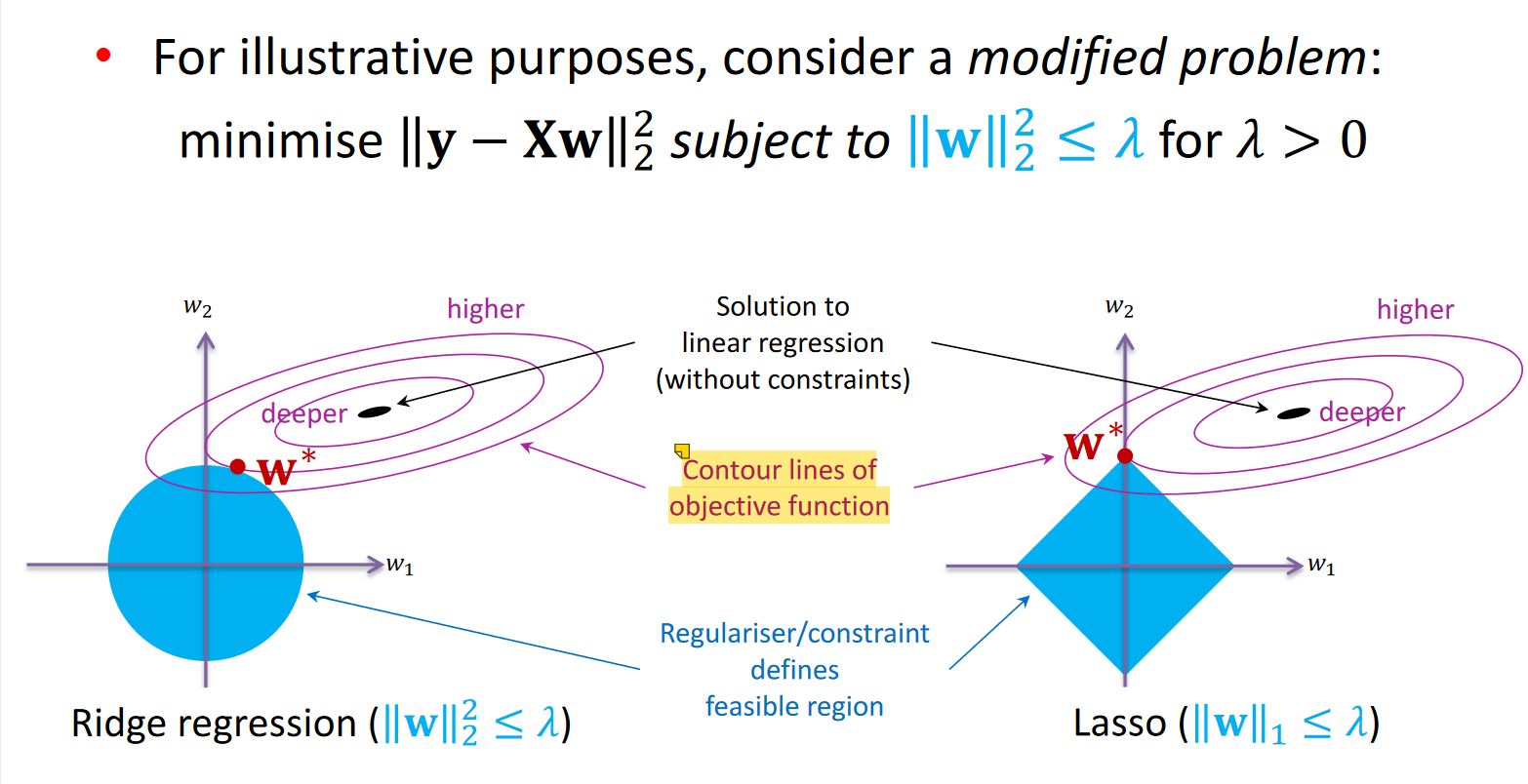
Lasso (L1 regularisation) encourages solutions to sit on the axes
Some of the weights are set to zero Solution is sparse