- simple model → low variance, high bias
- complex model → high variance, low bias
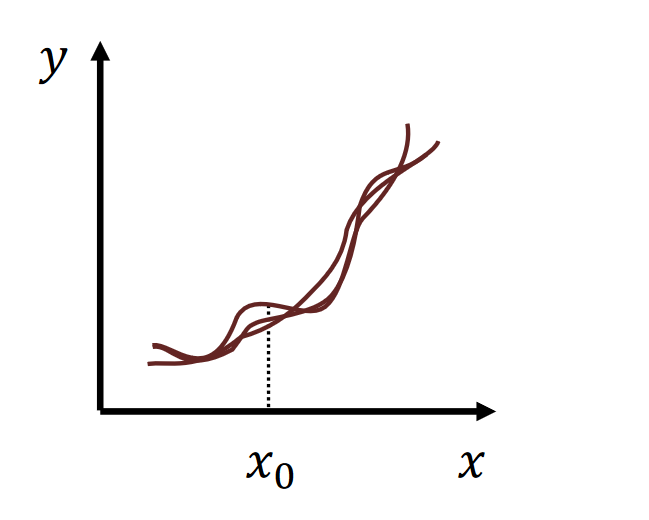 | 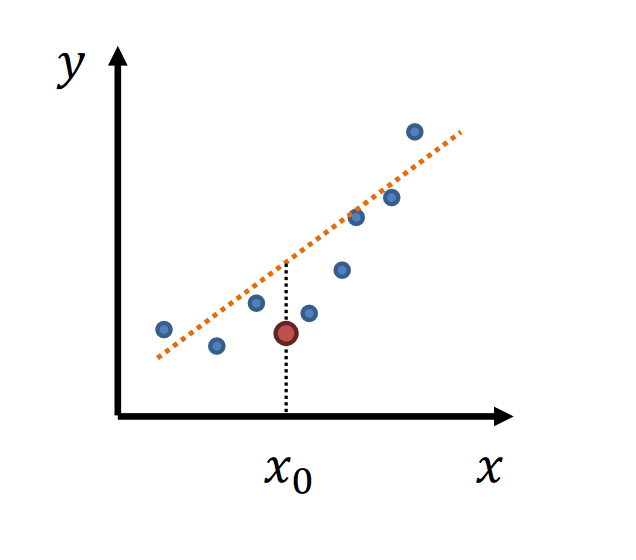 |
|---|
| high variance | high bias |
Testing and trainning error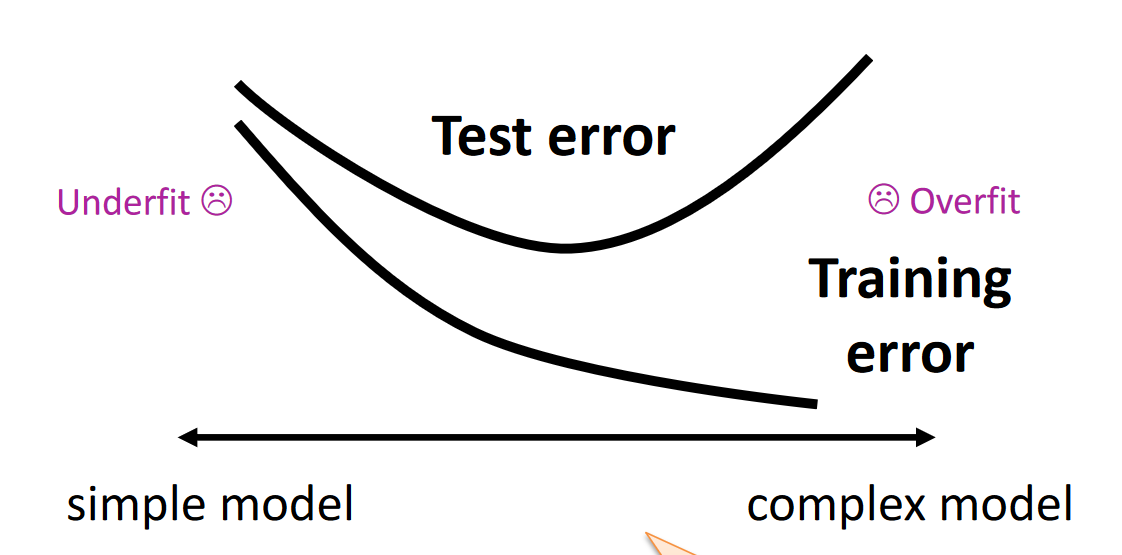
The true risk is the expected value of the loss 𝑙
R[f]=E[l(Y,f(X))]=∫l(Y,f(X))P(X,Y)dXdY
- l(Y,f(X)): Loss function
- P(X,y) joint distribution of input X and target Y
The empirical risk is an estimate (an average of a finite number of samples 𝑛) of the expected value
- sample size →∞, the true risk is the empirical risk
Structural Risk Minimisation
R^D[f^D]+2nlog∣F∣+log(1/δ)
F shatters {x1,x2} : Possible Labelings
- (0, 0)
- (0, 1)
- (1, 0)
- (1, 1)
If 1 of the 4 labels missing, F does not shatter {x1,x2}
The number of maximun shattering sets = VC(F)
if F shatters {𝑥1, 𝑥2, 𝑥4} and unique rows: 23=8, VC(F) = 3
Sauer-Shelah Lemma The Upper bound of growth function SF(n) given finite VC(F):
SF(n)≤i=0∑VC(F)(in)
Since ∑i=0k(in)≤(n+1)k, the above implies:
logSF(n)≤VC(F)log(n+1)
Structural Risk Minimisation(VC)(VC Generalisation Theorem)
R^D[f^D]+8nVC(F)log(2n+1)+log(4/δ)